
Python应用-判断单词-合并换行-自动Google翻译文献
研究生要写出好一点的论文,必然是要看许多的文献。当我们看外文文献,Google翻译就是个好帮手。即便如此,这其中依然少不了折腾。
1、背景
通常我们看到的论文是这样的:
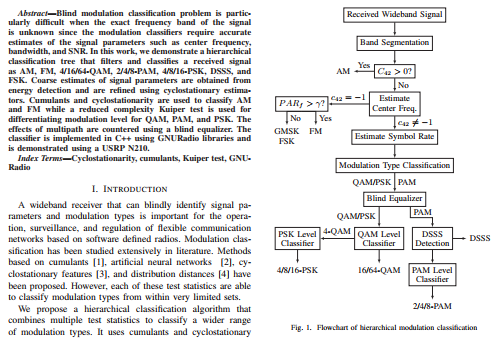
复制出来的文字粘贴到Google翻译结果是这样的:

2、逐步改进
2.1 原始时代
罪魁祸首是PDF论文的换行。手工逐个删除换行符,可以看到翻译结果明显准确了!只是重复的事情做多了也烦人!
2.2 石器时代
重复性的工作,机器最胜任了。最容易想到的办法:把文本复制到编辑器里,查找全局替换就好了。
以atom编辑器为例:
先要知道替换对象是什么,我们设置atom显示空白字符:
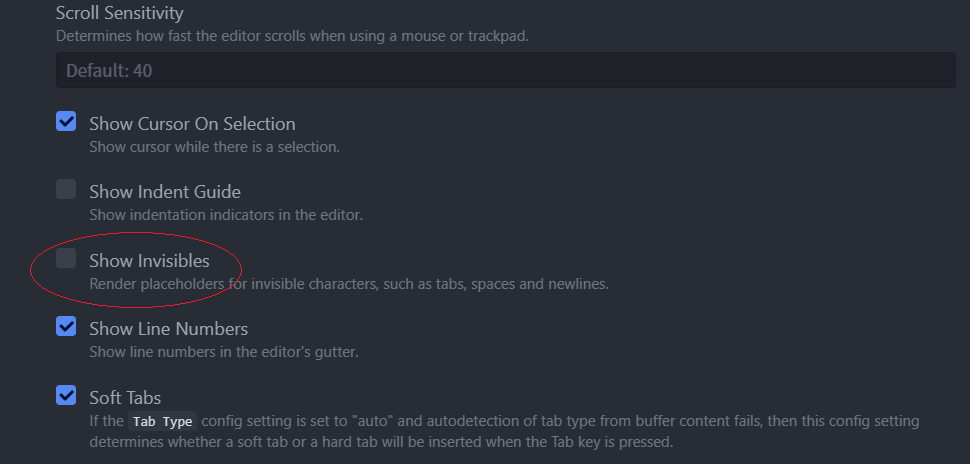
罪魁祸首’\r\n’显形了:
使用全局替换,这里注意必须使用正则表达式才能替换:

2.3 铁器时代
接来下文明大跃进,我们自己生产工具,这个工具就是–Python脚本,让他帮我们完成替换,步骤如下:
- 手动从PDF复制文本
- 工具自动替换粘贴板文本的’\r\n’
- 手动粘贴到Google翻译框
Python脚本定时监视粘贴板:
import pyperclip
import time
def altercopy():
tempBuff=' ' #仅仅用于暂存判定
while True:
time.sleep(3)
pasteText=pyperclip.paste()
if tempBuff != pasteText:
tempBuff=pasteText
strBuff=pasteText
strBuff = strBuff.replace('\r\n', ' ')
pyperclip.copy(strBuff) #修改粘贴板
tempBuff=strBuff #防止循环
至此省心了些。只要从PDF文献复制文本,等待一会粘贴到Google翻译框中,粘贴出的已经自动合并换行了。
2.4 蒸汽时代
使用过林格斯词典大多体验过这个功能:选中内容后词典会自动弹出翻译结果。类似的我们可以实现,复制了文本之后自动弹出Google翻译结果。
模拟步骤如下:
- 手动从PDF复制文本
- 工具自动替换粘贴板文本的’\r\n’
- 工具自动打开浏览器,访问Goolge翻译网页,翻译粘贴板内的文本
这里我们需要了解url的常识,在Goolge翻译网页输入hello,可以看到如下url:
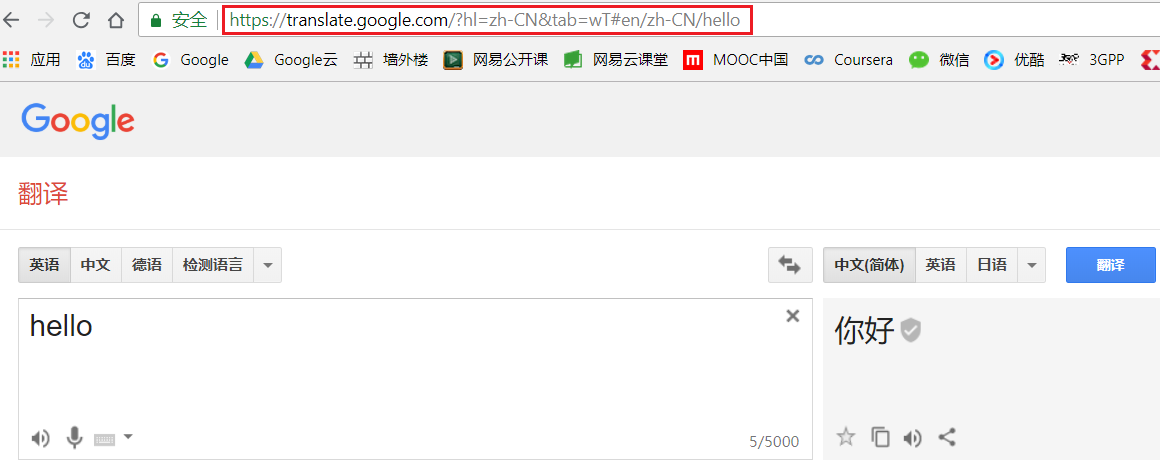
直观地看就是 https://translate.google.com/?hl=zh-CN&tab=wT#en/zh-CN/ + ‘hello’。也就是说访问https://translate.google.com/?hl=zh-CN&tab=wT#en/zh-CN/hello就可以把’hello’翻译’你好’。
import pyperclip
import time
def translation():
tempBuff=' ' #仅仅用于暂存判定
while True:
time.sleep(3)
pasteText=pyperclip.paste()
if tempBuff != pasteText:
tempBuff=pasteText
strBuff=pasteText
strBuff = strBuff.replace('\r\n', ' ')
url='https://translate.google.com/?hl=zh-CN&tab=wT#en/zh-CN/'+strBuff
chrome_path=r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" #r代表不转义,否则\需要替换为\\
webbrowser.register('chrome', None,webbrowser.BackgroundBrowser(chrome_path))
webbrowser.get('chrome').open(url)
现在只要从PDF文献复制文本,就会自动打开Google翻译标签页。看起来一切正常,不过当我们复制下面这一段文本:
In this work, we demonstrate a hierarchical classification tree that filters and classifies a received signal as AM, FM, 4/16/64-QAM, 2/4/8-PAM, 4/8/16-PSK, DSSS, and FSK. Coarse estimates of signal parameters are obtained from energy detection and are refined using cyclostationary estimators.
意外的得到了:
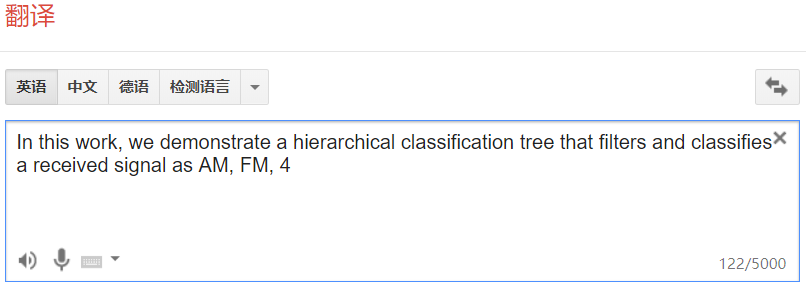
显然文本中 ‘/’ 和后面的内容都没有出现在Google翻译框中!这其实是url的规则把’/’当做解析字符处理了。解决这个问题需要特殊字符转义编码 :
| 原字符 | 转义编码 |
|---|---|
| + | %2B |
| ? | %3F |
| % | %25 |
| # | %23 |
| & | %26 |
这里注意转义编码需要避免重复转义,在这里就是’%’要最先转。代码如下:
import pyperclip
import time
def translation():
tempBuff=' ' #仅仅用于暂存判定
while True:
time.sleep(3)
pasteText=pyperclip.paste()
if tempBuff != pasteText:
tempBuff=pasteText
strBuff=pasteText
strBuff = strBuff.replace('\r\n', ' ')
strBuff = strBuff.replace('%', '%25') #url转义 %一定要在最前面
strBuff = strBuff.replace('+', '%2B')
strBuff = strBuff.replace('/', '%2F')
strBuff = strBuff.replace('?', '%3F')
strBuff = strBuff.replace('#', '%23')
strBuff = strBuff.replace('&', '%26')
url='https://translate.google.com/?hl=zh-CN&tab=wT#en/zh-CN/'+strBuff
chrome_path=r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" #r代表不转义,否则\需要替换为\\
webbrowser.register('chrome', None,webbrowser.BackgroundBrowser(chrome_path))
webbrowser.get('chrome').open(url)
2.5 电气自动化时代
以上我们只是机械地把换行替换为空格,有时候不仅有词间换行,也会有断字换行的情况,此时正确的处理应该是把换行替换为空字符。这里关键在于判断是否断字,等价于判断单词是否有效。这里我们大材小用一下 Natural language toolkit (NLTK) ,首次运行需要执行 nltk.download() ,在弹出的下载框中选择 package –> words –>download 。注意判断单词还需要兼顾单词 复数后缀 “s”、”es” 。
import pyperclip
import time
import nltk
#nltk.download() #首次运行需要开启并下载选择 package --> words -->download
from nltk.corpus import words as words_range
def translation():
tempBuff=' ' #仅仅用于暂存判定
while True:
time.sleep(3)
pasteText=pyperclip.paste()
if tempBuff != pasteText:
tempBuff=pasteText
strBuff=pasteText
while strBuff.find('\r\n') != -1:
lines= strBuff.split('\r\n',1)
line=lines[0]
words=line.rsplit(' ',1)
lastword=words[-1].lower()
if (lastword in words_range.words() or lastword.rstrip('s') in words_range.words() or lastword.rstrip('es') in words_range.words()):
strBuff = strBuff.replace('\r\n', ' ',1) #正常换行
else :
print(lastword)
strBuff = strBuff.replace('\r\n', '',1) #断词换行
strBuff = strBuff.replace('%', '%25') #url转义 %一定要在最前面
strBuff = strBuff.replace('+', '%2B')
strBuff = strBuff.replace('/', '%2F')
strBuff = strBuff.replace('?', '%3F')
strBuff = strBuff.replace('#', '%23')
strBuff = strBuff.replace('&', '%26')
url='https://translate.google.com/?hl=zh-CN&tab=wT#en/zh-CN/'+strBuff
chrome_path=r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" #r代表不转义,否则\需要替换为\\
webbrowser.register('chrome', None,webbrowser.BackgroundBrowser(chrome_path))
webbrowser.get('chrome').open(url)
运行示例: 复制文本:

启动脚本:
自动弹出的翻译网页:

复制新的想要翻译的段落,引发粘贴板内容发生变化,就会弹出新的Google翻译标签页。
3、感想
Python对字符串等序列的操作极其简明;各方面应用的支持库非常丰富。对于编程者构建实时性要求不高的日常辅助工具非常方便。
本例完整脚本代码可从auto_google_translationfork或download。